百度飞桨 PaddleOCR VL 与PP OCR 系列的区别
简单说:
PP-OCRv6 是“专业文字识别 OCR 模型”;PaddleOCR-VL-v1.6 是“文档解析/文档理解模型”。
它们都能处理图片/PDF 里的文字,但目标不一样。
1. 核心区别¶
| 对比项 | PP-OCRv6 | PaddleOCR-VL-v1.6 |
|---|---|---|
| 定位 | 通用 OCR 文字检测+识别 | 复杂文档解析/文档理解 |
| 主要任务 | 找到文字区域并识别文字 | 解析文本、表格、公式、图表、印章、版面结构 |
| 模型形态 | 轻量级 OCR 系统 | 视觉语言模型/VLM 文档解析模型 |
| 优势 | 快、轻、部署方便、适合工业/业务 OCR | 对复杂文档结构理解更强 |
| 适合输出 | 纯文本、文字框、识别结果 | Markdown、结构化文档、表格/公式/图表等复杂元素 |
| 部署侧重 | 端侧、移动端、服务端均可 | 更偏服务端/高质量文档解析 |
PP-OCRv6 官方定位是“全场景多语言文字识别”,单模型支持 50 种语言,并提供 tiny/small/medium 三档模型,参数量从 1.5M 到 34.5M,分别覆盖端侧、移动端和服务端部署;它还重点增强了数码屏、点阵字符、轮胎印字、工业字符等专业 OCR 场景。(paddlepaddle. github. io)
PaddleOCR-VL-v1.6 则是基于 PaddleOCR-VL-v1.5 升级的紧凑文档解析模型,重点提升复杂文档解析能力,在 OmniDocBench v1.6 上达到 96.33%,并在文本、公式、表格、古籍、生僻字、印章、图表理解等场景上增强。(GitHub)
2. PP-OCRv6 面向什么场景?¶
PP-OCRv6 更适合你可以明确称为“OCR”的场景:
它的关键词是:
| Text Only | |
|---|---|
比如你做 RAG 系统,用户上传扫描件 PDF,你只是想把页面里的文字提取出来,再做分块、向量化、入库,那么 PP-OCRv6 通常更合适。
3. PaddleOCR-VL-v1.6 面向什么场景?¶
PaddleOCR-VL-v1.6 更适合“复杂文档解析”,不只是把字认出来,还要理解文档元素和结构:
| Text Only | |
|---|---|
它的关键词是:
| Text Only | |
|---|---|
官方对 PaddleOCR-VL 系列的描述就是面向文档解析,支持多语言,并在文本、表格、公式、图表等复杂元素识别方面表现突出。(paddlepaddle. github. io)
4. 在 RAG 项目里怎么选?¶
如果你的目标是:
| Text Only | |
|---|---|
优先选:
| Text Only | |
|---|---|
因为它轻、快、部署成本低。
如果你的目标是:
优先选:
| Text Only | |
|---|---|
因为它更像“文档解析模型”,不是单纯 OCR。
5. 更实用的组合方案¶
对你的 RAG 文件处理流程,可以这么设计:
| Text Only | |
|---|---|
一句话总结:
PP-OCRv6 适合做高效文字识别,PaddleOCR-VL-v1.6 适合做复杂文档解析。前者更像 OCR 基础能力,后者更像面向 PDF/文档理解的多模态解析能力。
附:PaddleOCR-VL 与 PP-OCR 效果图¶
PaddleOCR-VL-1.6 效果图 1
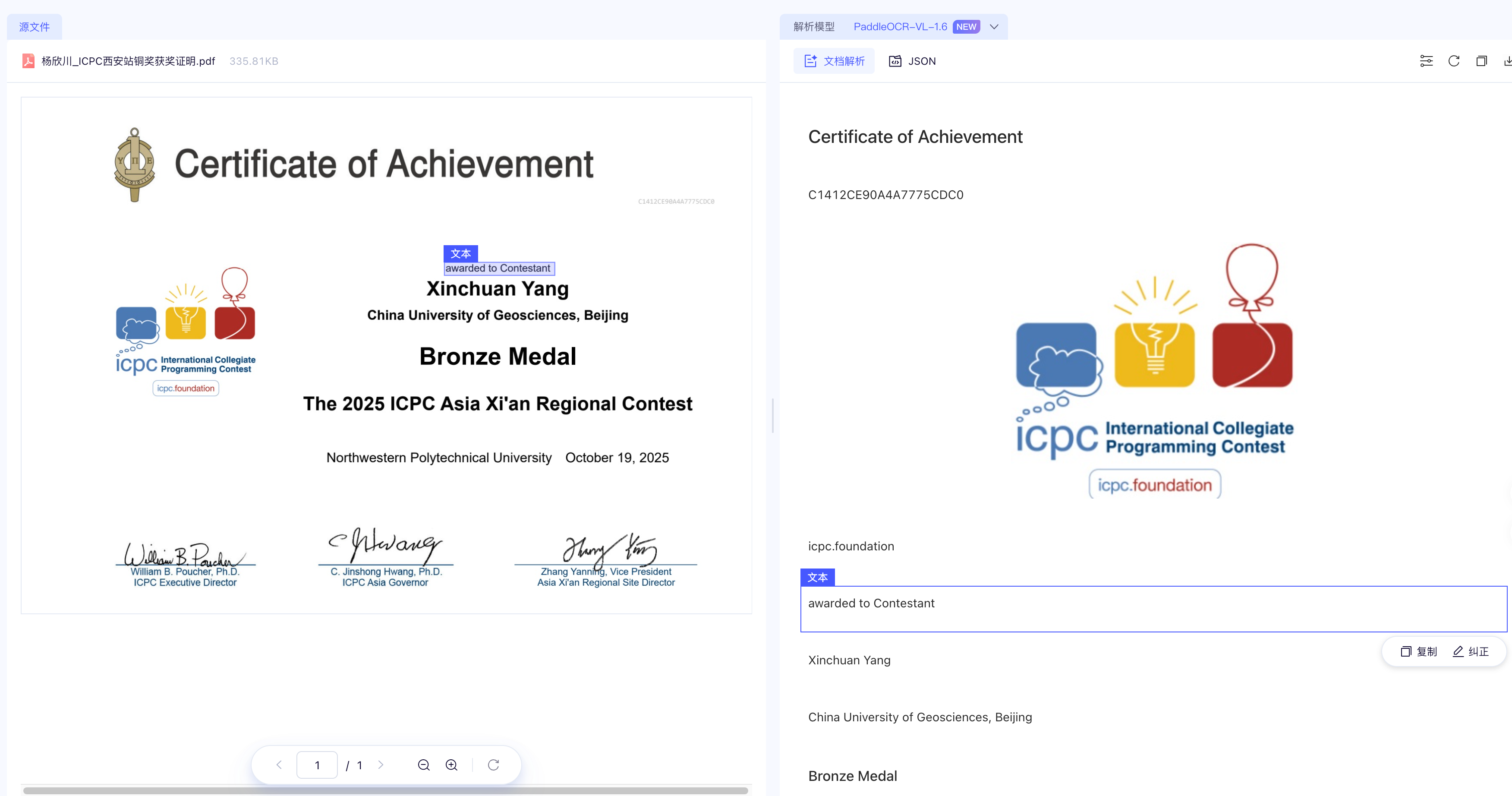
PaddleOCR-VL-1.6 效果图 2

PP-OCRv6 效果图 1
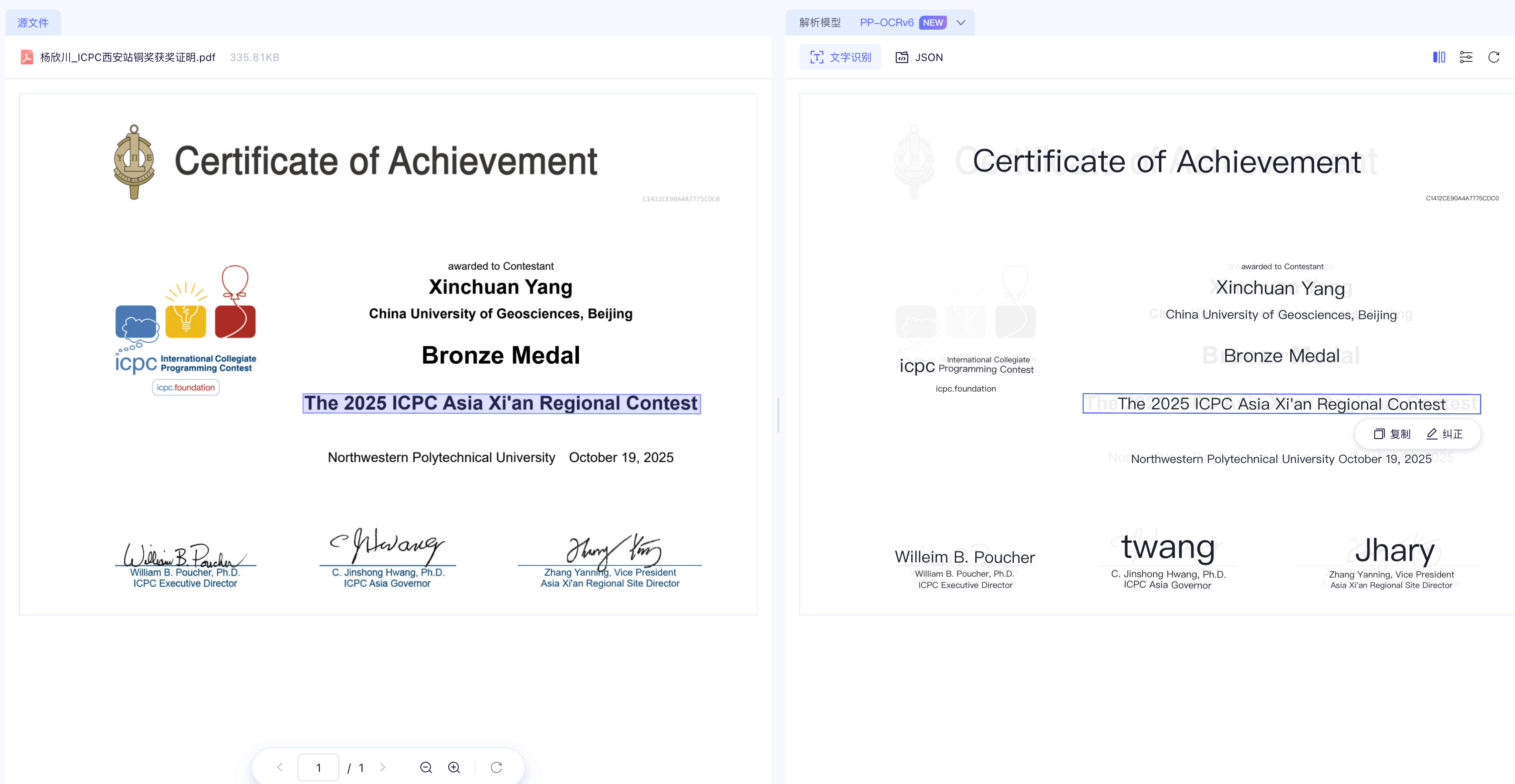
PP-OCRv6 效果图 2
